
这篇文章讨论了超低延迟(ULL)通信的重要性以及低延迟智能网卡的设计思路。作者首先提到了高频交易机构最早采用智能网卡来降低延迟,并且这一技术后来也被应用于其他领域,如人工智能训练。文章分析了几种常见的低延迟解决方案,包括Kernel Bypass、UDP Market Data Parser和TCP Offload Engine(TOE)。
作者进一步介绍了高频交易的常见业务模式,包括分离接口、行情过滤和重新编码。然后,文章讨论了传统CPU报文处理的缺陷,特别是报文解析的延迟,以及如何通过P4和硬件加速来降低这些延迟。
文章提到了两家公司,Pensando和Fungible,它们采用了不同的架构来处理报文,并提供了对这些架构的详细解释。Pensando的架构包括P4流水线引擎和本地缓存,以提高报文处理效率。而Fungible采用了Data Cluster结构,支持RTC编程,兼容C代码程序,同时采用了DAG处理方式,以实现低延迟和高并行。
最后,作者总结了文章的主要观点,即可以借鉴Pensando和Fungible等公司的思路和技术,通过优化FPGA网卡的设计和工具链来降低延迟,同时需要在高并行性和灵活性之间做出权衡。文章为那些对低延迟智能网卡设计感兴趣的读者提供了有用的思考和参考。
本文由攜程資深技術支持工程師 Yellowsea 撰寫,主要講述了如何利用開源的 DPVS(基於 DPDK 的 LVS)構建攜程的高性能四層軟件負載均衡 TDLB (Trip.com Dpdk LoadBalancer)。以下是文章的簡介:
-
背景:
- 在攜程的服務流量接入架構中,四層負載均衡扮演著關鍵角色。隨著業務流量的不斷增長,原硬件四層負載均衡面臨成本高、採購周期長和 HA 工作模式等問題,因此攜程急需在開源社區中尋找高性能四層負載均衡軟件化的解決方案【24†source】。
-
TDLB 高性能實現:
- 文章探討了 TDLB 如何通過 DPDK 解決傳統 LVS 負載均衡的性能瓶頸。利用 DPDK 的 kernel bypass 設計,避免了内核态与用户态的切换耗时问题,提升了处理数据包时 cache 的命中率。
- 此外,TDLB 在会话无锁方面作了优化,通过 percore 的会话设计避免了 core 与 core 之间的资源竞争,保证了入向流量与出向流量分配至同一个 core【24†source】。
-
用戶源 IP 透傳:
- 文章也探讨了两种主要的用户源 IP 透传方式:TOA 和 ProxyProtocol,这两种方法分别需要在服务器上挂载 TOA 相应的 kernel module 或在服务的应用层提供 ProxyProtocol 的支持【24†source】。
本文適合對 DPDK 和負載均衡有興趣,並希望了解如何在实际业务中应用 DPDK 以提升四層負载均衡性能的讀者。透過閱讀本文,讀者可以了解到 DPDK 在实际业务中的应用,以及如何解决传统 LVS 负载均衡的性能瓶颈。
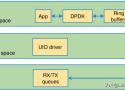
文章的主要內容是關於 Intel® DPDK (Data Plane Development Kit) 的基本原理和學習路線的總結。以下是對文章的摘要:
-
DPDK 簡介:
- DPDK 是 Intel 提供的數據平面開發工具集,主要為 Intel 架構下的用戶空間高效的數據包處理提供庫函數和驅動的支持。
- 透過 DPDK, 程序能夠在用戶空間上利用 DPDK 提供的數據平面庫來收發數據包,繞過了 Linux 內核協議棧對數據包處理過程,從而提高數據處理效率【14†(來源)】。
-
DPDK 技術特點:
- UIO (Linux Userspace I/O) 使得網卡驅動能在用戶空間運行,降低了報文在用戶空間和應用空間的多次拷貝,並能顯著提升虛擬化網絡設備的數據採集效率【14†(來源)】。
-
用戶空間輪詢模式(PMD):
- DPDK 的用戶空間輪詢模式驅動使得應用程序不需經過 Linux 內核即可訪問網絡設備卡,從而省去了內核到應用層的數據包拷貝過程,提高了數據處理效率【18†(來源)】。
-
DPDK 的核心思想:
- 用戶態模式下的 PMD Driver 能夠去除中斷影響,減少操作系統內核的開銷,消除 IO 吞吐瓶頸,並在用戶態下的軟件崩潰時不會影響系統的穩定性【18†(來源)】。
-
學習路線:
- 文章也提及了 DPDK 的學習路線,但並未提供具體的學習資源或建議。
-
結論:
- 通過理解和應用 DPDK,開發人員可以在網絡應用中實現高性能的數據包處理,提高數據處理效率和系統性能。
這篇文章非常適合對 DPDK 感興趣,並希望了解其基本原理和技術特點的讀者。

在優化TCP以實現高通量和低延遲方面,Cloudflare的博客文章提供了非常詳盡的解釋和策略。以下是文章的主要內容:
-
性能調優:
- Cloudflare的工程師通過監視數百個流量參數來不斷改善他們的服務,其中HTTP請求延遲是他們密切關注的核心數字。他們將延遲峰值視為需要修復的錯誤,例如在2017年,他們通過優化TCP接受隊列來改善等待接受的TCP套接字的整體延遲。
-
通過調整
tcp_rmem解決延遲峰值:- 在2015年,他們在處理HTTP請求時發現了延遲峰值。當時的解決方案是將
tcp_rmem設置為4 MiB,以最小化內核在TCP崩潰處理上的時間花費。但這種設置限制了高延遲連接上的TCP通量【122†source】。
- 在2015年,他們在處理HTTP請求時發現了延遲峰值。當時的解決方案是將
-
TCP接收窗口和
tcp_adv_win_scale:- TCP接收窗口是在任何時候發送者應傳輸的未確認用戶有效載荷字節的最大數量。接收窗口的大小會在TCP會話期間上下波動。
tcp_adv_win_scale是用於解釋接收窗口中的用戶有效載荷字節所需的額外內存的值。接收窗口的值會根據接收緩衝區中的可用內存量而變化【122†source】。
- TCP接收窗口是在任何時候發送者應傳輸的未確認用戶有效載荷字節的最大數量。接收窗口的大小會在TCP會話期間上下波動。
-
Linux自動調整:
- Linux自動調整是Linux內核中的邏輯,它根據實際的封包處理情況來調整緩衝區大小限制和接收窗口。它考慮了多種因素,包括TCP會話的RTT,L7讀取速率和可用的主機內存量。自動調整可以通過跟踪本地應用程序從接收隊列中讀取數據的速率以及會話RTT,來自動增加緩衝區和接收窗口,直到應用程序層或網絡瓶頸鏈接成為通量限制因素為止【122†source】。
這篇文章通過解釋TCP的核心機制和Linux的自動調整功能,以及Cloudflare如何解決特定的延遲問題,提供了關於如何在保持低延遲的同時實現高通量的深入見解。該文章對於有興趣理解和優化TCP性能的讀者來說是一個很好的資源。

這篇博客描述了一個在Linux環境下如何接收每秒一百萬個UDP數據包的實驗,並探討了Linux網絡堆棧的性能。
整個博客旨在通過實際實驗來探索和優化Linux網絡堆棧的性能,對於有網絡編程背景或對網絡性能優化感興趣的讀者來說,這是一個很好的學習資源。透過這篇博客,讀者可以了解到Linux網絡堆棧的基本工作原理,以及如何通過實驗和優化來提高網絡性能。

該網誌文章描述了如何通過優化一個基於UDP的應用來實現低延遲,尤其是在10Gbps以太網環境中。以下是文章的重點:
-
實驗設置:
- 使用兩台物理Linux主機,一台作為客戶端,另一台作為服務器,通過簡單的UDP回聲協議進行通信。
- 客戶端發送一個小的UDP幀(32字節的有效負載),並等待回復,測量往返時間(RTT)。服務器在收到封包後立即回送。
- 確保
iptables和conntrack不干擾流量,並手動分配多隊列網絡卡的中斷以保證它們在CPU之間均勻分配【98†(Cloudflare Blog)】。
-
低延遲設置:
- 設置如低
rx-usecs或禁用LRO可能會減少吞吐量並增加中斷的次數,這意味著為低延遲優化系統可能會使其更容易受到服務拒絕攻擊的影響【102†(Cloudflare Blog)】。
- 設置如低
-
低延遲的其他考慮因素:
- 在無線網絡中,低延遲可以通過不同的無線應用在私人5G,Wi-Fi和Cisco超可靠無線回程(URWB)部署中實現。影響端到端延遲的因素包括雲或數據中心的接近程度以及降低延遲的優化【103†(Cisco)】。
- 測量網絡通信從起點到完成需要多長時間是改善網絡延遲的第一步。網絡經理可以選擇多種工具來完成這項任務,包括Ping,Traceroute和My traceroute(MTR)【104†(TechTarget)】。
- 適當的網絡設計是延遲的一個功能。無線延遲必須與端到端的IP延遲和往返延遲一起考慮。應用程序位於哪裡,數據在數據中心,雲或網絡邊緣被處理的地方越接近,可能的延遲就越低【105†(Cisco Blogs)】。
通過這些步驟和考慮因素,開發人員和網絡工程師可以優化他們的系統以實現低延遲,從而提高應用程序的性能和用戶體驗。

这篇文章主要讨论了设计借贷宝底层k8s架构时面临的一些挑战和解决方案,包括使用macvlan网络插件、clusterip的实现机制以及如何让管理Pod正常运行的问题。以下是摘要、结论和适合阅读的客群:
摘要:
本文探讨了在设计借贷宝底层k8s架构时遇到的一些问题,特别是关于如何使用macvlan网络插件以及如何处理管理Pod的网络访问问题。文章提供了关于clusterip的实现机制和macvlan网络的限制的详细分析,并提出了解决方案,包括使用hostnetwork和multus-cni插件。
结论:
在解决问题1时,文章强调了clusterip的实现机制,并讨论了macvlan网络为何不能直接使用clusterip。虽然可以对macvlan进行改造以实现这一目标,但改造过程复杂,不划算。文章建议使用hostnetwork来解决管理Pod的网络访问问题,因为大部分管理Pod可以通过hostnetwork正常运行,而不需要macvlan网络。
在解决问题2和问题3时,文章提供了两种解决方案,一是将部分Node标记为master,采用cluster network,另一是使用multus-cni插件创建双网卡配置,其中一个网卡使用macvlan网络,另一个使用cluster network。作者倾向于第一种解决方案,因为它不需要双网卡配置,并且更符合他们的需求。
适合阅读的客群:
本文适合那些对k8s架构和网络配置有一定了解的技术人员,特别是对macvlan网络和clusterip实现机制感兴趣的读者。文章提供了详细的技术分析和解决方案,适合深入研究和实践相关领域的专业人士。