GlitchTip is an open source, Sentry API compatible error tracking platform.
全闪NAS(5*M.2 NVMe)暨软路由AIO,N100作业,前言这是一份历时三个月的作业。联芸MAP1602+长江存储232L的国货精品,省电(待机不到0.1瓦 , 峰值最高3.98瓦)、省钱(999/4TB、499/2TB)、省空间(M.2 2280),掀开了 ...,原创分享(新),分享区-产品开箱与用户体验的分享 ,Chiphell - 分享与交流用户体验

衛福部「年輕族群心理健康支持方案」8月起補助15~30歲民眾3次免費諮商,但半個月後名額就快用完、得緊急加碼。第一線心理師和地方政府遭遇什麼挑戰?被篩選出的年輕族群高風險個案,未來有何資源和方法能承接?

Lessons from a Meta tech lead and Staff Engineer

Build Your Own Network Attached Storage (BYO-NAS) Takes advantage of the natural heat conductivity and dissipation of the aluminum Augmented the built-in controllable fan to cool down both the Raspberry Pi and hard disks Multi-function power button to allow for seamless integration with the case Programmable OLED Displ

SATA Board for Raspberry Pi CM4是款專為Raspberry PI 4運算模組設計的擴充板,提供4組SATA端子,以及1組GbE乙太網路,能夠用於土砲NAS等裝置。

Rock Pi SATA HAT是款能相容於Raspberry Pi 4或Rock Pi 4的硬碟擴充套件,最多能支援同時連接5顆SATA傳統硬碟或固態硬碟,具有高達803MB/s的傳輸效能,並可搭配控制面板與專屬機殼,大幅提升資料儲存總容量。

Here is a brief story about how you can use the Do’s and Don’ts of alerting for your team or company.
文章指出產品經理的角色是一個錯誤,認為一個成功的產品公司應由有遠見的人領導而非一個職業產品經理。它解釋,偉大的領袖如賈伯斯或馬斯克從未是產品經理,他們由對願景的熱情驅動,而非資料或KPIs。文章警告,聘用缺乏願景的產品經理可能導致過度依賴數據,官僚主義,以及組織中低效的溝通和協作

The Intel N100 (and N200) seem to be Intel's attempt at trying to muscle into the market that high-end ARM SoCs look to have cornered. With the Rockchip

理解我这一个观点,我们来说一下 Python 的几大痛点:
- Python 的可调式性,可观测性问题。历史上 Python 中做 Cost 的消耗极大,同时没有足够的手段可以从旁路去观察 Python 的运行时行为
- Python GIL 问题,这个老生长谈了,不多说
- Python 的 C API/ABI 问题,之前暴露的 C API/ABI 通常和 CPython VM 实现细节耦合,导致跨版本兼容性会是一个问题
而这样一些问题,Python 3.12 上都有了极大的进步
- PEP 669, GH-96143 极大提升了 Python 的可观测性,可调式性
- PEP 684, A Per-Interpreter GIL, 提升 Python 进程内性能,为后续的 non-GIL 打下了良好的基础
- PEP 697 全新的 C API,进一步解耦 API/ABI 与 CPython VM 实现细节的耦合
PTR, SPF, DKIM, DMARC

这篇文章讨论了超低延迟(ULL)通信的重要性以及低延迟智能网卡的设计思路。作者首先提到了高频交易机构最早采用智能网卡来降低延迟,并且这一技术后来也被应用于其他领域,如人工智能训练。文章分析了几种常见的低延迟解决方案,包括Kernel Bypass、UDP Market Data Parser和TCP Offload Engine(TOE)。
作者进一步介绍了高频交易的常见业务模式,包括分离接口、行情过滤和重新编码。然后,文章讨论了传统CPU报文处理的缺陷,特别是报文解析的延迟,以及如何通过P4和硬件加速来降低这些延迟。
文章提到了两家公司,Pensando和Fungible,它们采用了不同的架构来处理报文,并提供了对这些架构的详细解释。Pensando的架构包括P4流水线引擎和本地缓存,以提高报文处理效率。而Fungible采用了Data Cluster结构,支持RTC编程,兼容C代码程序,同时采用了DAG处理方式,以实现低延迟和高并行。
最后,作者总结了文章的主要观点,即可以借鉴Pensando和Fungible等公司的思路和技术,通过优化FPGA网卡的设计和工具链来降低延迟,同时需要在高并行性和灵活性之间做出权衡。文章为那些对低延迟智能网卡设计感兴趣的读者提供了有用的思考和参考。
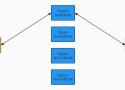
本文由攜程資深技術支持工程師 Yellowsea 撰寫,主要講述了如何利用開源的 DPVS(基於 DPDK 的 LVS)構建攜程的高性能四層軟件負載均衡 TDLB (Trip.com Dpdk LoadBalancer)。以下是文章的簡介:
-
背景:
- 在攜程的服務流量接入架構中,四層負載均衡扮演著關鍵角色。隨著業務流量的不斷增長,原硬件四層負載均衡面臨成本高、採購周期長和 HA 工作模式等問題,因此攜程急需在開源社區中尋找高性能四層負載均衡軟件化的解決方案【24†source】。
-
TDLB 高性能實現:
- 文章探討了 TDLB 如何通過 DPDK 解決傳統 LVS 負載均衡的性能瓶頸。利用 DPDK 的 kernel bypass 設計,避免了内核态与用户态的切换耗时问题,提升了处理数据包时 cache 的命中率。
- 此外,TDLB 在会话无锁方面作了优化,通过 percore 的会话设计避免了 core 与 core 之间的资源竞争,保证了入向流量与出向流量分配至同一个 core【24†source】。
-
用戶源 IP 透傳:
- 文章也探讨了两种主要的用户源 IP 透传方式:TOA 和 ProxyProtocol,这两种方法分别需要在服务器上挂载 TOA 相应的 kernel module 或在服务的应用层提供 ProxyProtocol 的支持【24†source】。
本文適合對 DPDK 和負載均衡有興趣,並希望了解如何在实际业务中应用 DPDK 以提升四層負载均衡性能的讀者。透過閱讀本文,讀者可以了解到 DPDK 在实际业务中的应用,以及如何解决传统 LVS 负载均衡的性能瓶颈。
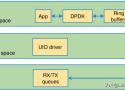
文章的主要內容是關於 Intel® DPDK (Data Plane Development Kit) 的基本原理和學習路線的總結。以下是對文章的摘要:
-
DPDK 簡介:
- DPDK 是 Intel 提供的數據平面開發工具集,主要為 Intel 架構下的用戶空間高效的數據包處理提供庫函數和驅動的支持。
- 透過 DPDK, 程序能夠在用戶空間上利用 DPDK 提供的數據平面庫來收發數據包,繞過了 Linux 內核協議棧對數據包處理過程,從而提高數據處理效率【14†(來源)】。
-
DPDK 技術特點:
- UIO (Linux Userspace I/O) 使得網卡驅動能在用戶空間運行,降低了報文在用戶空間和應用空間的多次拷貝,並能顯著提升虛擬化網絡設備的數據採集效率【14†(來源)】。
-
用戶空間輪詢模式(PMD):
- DPDK 的用戶空間輪詢模式驅動使得應用程序不需經過 Linux 內核即可訪問網絡設備卡,從而省去了內核到應用層的數據包拷貝過程,提高了數據處理效率【18†(來源)】。
-
DPDK 的核心思想:
- 用戶態模式下的 PMD Driver 能夠去除中斷影響,減少操作系統內核的開銷,消除 IO 吞吐瓶頸,並在用戶態下的軟件崩潰時不會影響系統的穩定性【18†(來源)】。
-
學習路線:
- 文章也提及了 DPDK 的學習路線,但並未提供具體的學習資源或建議。
-
結論:
- 通過理解和應用 DPDK,開發人員可以在網絡應用中實現高性能的數據包處理,提高數據處理效率和系統性能。
這篇文章非常適合對 DPDK 感興趣,並希望了解其基本原理和技術特點的讀者。

Where I've spent way too much time creating benchmarks of C++ hashmaps
In this articles we investigate on how branches influence the performance of the code and what can we do to improve the speed of our branchfull code.文章主要探討了程式碼中分支結構對性能的影響,以及開發人員如何優化這些分支以提高效能。摘要如下:
-
摘要:
- 程式碼中的分支結構可能會導致預測失敗,進而影響程序的性能。分支預測失敗的成本可能會很高,特別是在迴圈和函數呼叫中。
- 分析工具能幫助開發人員識別和優化分支,從而提高程式碼的性能。
-
結論:
- 通過瞭解和優化分支結構,開發人員能夠縮短執行時間,提高程式的效率。有效的分支預測和優化是達成高性能程式碼的關鍵。
-
適合閱讀的對象:
- 此文章適合具有一定程式設計經驗,並且希望了解如何優化程式碼性能的開發人員閱讀。透過瞭解分支結構的工作原理以及如何優化它們,開發人員能夠撰寫出更高效的程式碼。
這篇文章提供了實用的資訊和策略,對於希望提高程式碼效能的開發人員來說,值得一讀。
这篇文章讨论了系统和网络调优,特别关注Linux服务器的低延迟技术。作者提到了知乎上关于这一主题的讨论不够充分,并分享了自己的见解。文章分为两部分,本文主要涵盖系统调优,另一篇将探讨网络调优,特别是使用solarflare网卡来降低网络IO延迟。
文章的重点在于强调延迟的稳定性对于实时任务的重要性。作者提到了"kernel bypass",即绕过内核处理,以降低延迟。在实时任务中,避免进入内核,避免中断的关键,因为即使中断发生时线程是空闲的,CPU缓存也会被污染,从而影响下一次请求的延迟。
作者分享了一些修改系统设置的方法,如绑定关键线程到特定核心,避免中断源向核心发送中断等。此外,他提到了通过修改内核以延长中断发送周期来进一步提高延迟稳定性的可能性。
文章最后提到了两个原则:一是如果可以推迟一件事情,就应该推迟,二是不要为不使用的东西付费,这在性能优化方面尤为重要。
适合阅读这篇文章的对象包括对Linux服务器性能调优和低延迟技术感兴趣的系统工程师和网络工程师,特别是那些需要处理实时任务和对延迟稳定性有高要求的人员。文章提供了一些有用的见解和方法,可用于优化系统以降低延迟。
这篇文章主要探讨了关于Linux网络IO低延迟方案,特别是针对solarflare高性能网卡的使用经验。文章提到了三种与solarflare相关的kernel bypass软件解决方案:Onload、ef_vi和Tcpdirect,并分享了对它们性能的测试结果和个人使用感受。
作者提到了对这些解决方案进行了实际测试,特别是通过实现一个贴合实际的echo测试来测量延迟。在测试中,作者发现最佳的延迟约为960ns +/- 90ns,使用了最新的X2系列网卡、ef_vi接收UDP、Tcpdirect发送TCP,并采用了屏蔽中断的内核优化。
此外,文章还简要谈到了对三个不同的stack的使用感受:
- Onload:易用性强,适合新手入门,性能相对较好。
- ef_vi:提供最佳性能,但API较复杂,适合专业用户。
- Tcpdirect:基于ef_vi,提供上层协议支持,适合UDP发送端和整个TCP使用。
最后,文章提到了如何测量网卡到网卡的延迟,包括使用交换机镜像、tap设备、本地抓包工具等不同方法,并详细讨论了各种本地记录网络包时间戳的方法,包括tcpdump、onload_tcpdump、solar_capture、通过ef_vi/tcpdirect API获取网卡时间戳、sfptpd等。
总的来说,这篇文章提供了关于Linux网络IO低延迟方案以及solarflare网卡的使用经验和测试结果,对于需要优化网络性能的开发者和工程师可能会有一定参考价值。
The Startup CTO's Handbook, a book covering leadership, management and technical topics for leaders of software engineering teams